
UUID v8: надёжная миграция ID в микросервисах
При миграции от монолита к микросервисам встал вопрос: как перенести миллионы записей с числовыми ID на UUID без потерь в скорости и совместимости? Решением стал UUID v8 — он кодирует legacy ID, тип сущности и хэш, обеспечивая детерминированность и надёжность миграции.
В процессе перехода от монолитной архитектуры к микросервисной возникла фундаментальная проблема: как эффективно мигрировать миллионы существующих записей с числовыми ID к новой системе идентификации, основанной на UUID, не теряя при этом производительность и обеспечивая совместимость с существующей инфраструктурой.
Первое решение: CDC и централизованный генератор идентификаторов
На старте миграции от монолита к микросервисной архитектуре мы использовали паттерн CDC (Change Data Capture) для отслеживания изменений данных в базе данных монолита и передачи этих изменений в реальном времени другим системам и микросервисам.
Решено было генерировать новые uuid в одном сервисе, применив паттер ID Generator / Identity Service / Генератор идентификаторов. Назовем этот сервис CDC-адаптером.
Монолит (int ID) → CDC Service → UUID v7 Generator → Kafka Topic → Микросервисы
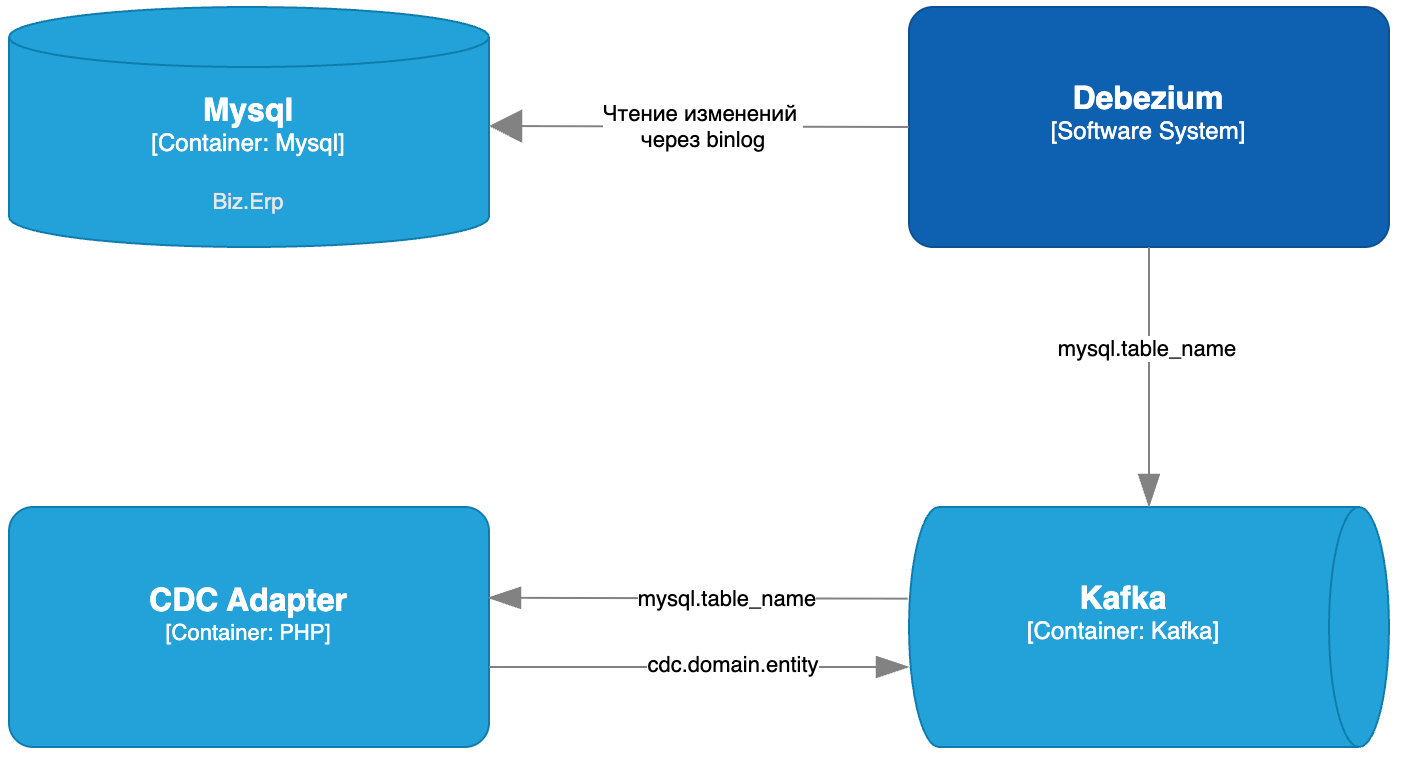
CDC-адаптер выполнял две ключевые функции:
- Генерация UUID v7 — выдавал уникальный идентификатор для каждой записи
- Хранилище маппинга — сопоставлял старые числовые ID с новыми UUID, обеспечивая единый источник правды для всей системы
Как работал CDC Adapter
CDC-адаптер подписывался на топики Kafka, получающие события от Debezium. Для каждой сущности:
- Проверялся legacy ID в payload:
- Если сущность новая — генерировался UUID v7
- Если сущность уже существует — UUID извлекался из базы данных
- Выполнялся маппинг полей для целевого микросервиса
- Обработанная сущность отправлялась в соответствующий топик микросервиса
Преимущества данного подхода
- Все сущности имели канонический UUID, который не менялся при повторной обработке
- Можно было легко сопоставлять соответствия между старой и новой системой генерации ID сущностей
Критические узкие места применения CDC-адаптера
- Высокая задержка: каждое изменение проходило дополнительный хоп через сервис, добавляя около 200 ms к операции — неприемлемо для высоконагруженной системы
- Единая точка отказа: сбой CDC Adapter блокировал бы обработку данных по всем микросервисам
- Сложность масштабирования: рост нагрузки превращал сервис в узкое место
Пересмотр требований в поисках альтернативных решений
Поработав с CDC-адаптером и получив первый опыт, мы решили заново провести обзор альтернатив. На это так же повлияли неудобства в работе и накладываемые ограничения на проведение миграций. Приходилось выполнять процесс миграции на нескольких окружениях, для предбоевого окружения миграция занимала уже значительное время. CDC-адаптер стал ощущаться бутылочным горлышком и в процессе разработки.
Почему изначально выбрали UUID v7
UUID v7 на первый взгляд выглядел идеальным решением: он основан на временной метке, обеспечивает сортируемость и хорошо документирован в стандарте. Но у него есть критическое ограничение — он не позволяет встроить внутрь себя числовой идентификатор из legacy системы.
В контексте миграции это означает, что при первом переносе данных все сущности получают новые UUID v7, которые никак не связаны с их старыми числовыми ID. Проблема проявляется в том, что UUID v7 всегда генерируется заново и не имеет детерминированности относительно legacy ID.
Теперь представим ситуацию: произошёл сбой, и нам нужно выполнить миграцию повторно (например, откат данных или пересоздание микросервисной базы). В этой новой миграции те же самые записи получат другие UUID v7, так как генерация основана на времени и случайных компонентах.
В результате:
- В микросервисах могли уже сохраниться ссылки на старые UUID v7
- При повторной миграции те же сущности получат другие идентификаторы
- Это создаёт жёсткую связанность между данными и временем миграции, а не с самим legacy ID
- Любое несоответствие приводит к рассинхронизации: одна и та же сущность в разных системах может иметь разные UUID
Таким образом, при использовании UUID v7 возникал риск, что после любого отката или повторной миграции пришлось бы «склеивать» данные вручную, поддерживать дополнительные таблицы соответствия или даже переписывать ссылки в микросервисах. Это делало систему хрупкой, зависимой от единовременной миграции и существенно повышало сложность поддержки.
Альтернатива: переход на UUID v8
UUID v8 — это «конструктор» в мире UUID. Он позволяет создавать собственные алгоритмы генерации идентификаторов, при этом сохраняя совместимость со стандартом RFC 9562.
Главное отличие: мы можем сами задавать, какие данные будут закодированы в биты UUID. Это позволило нам:
- Встроить в UUID флаг Legacy ID, чтобы отличать старые сущности от новых
- Сохранить в UUID сам int ID (32 бита), обеспечив детерминированное сопоставление
- Добавить тип сущности (например, staff, location), что упростило маршрутизацию данных между сервисами
- Усилить уникальность с помощью SHA-256 хэша, который занимает оставшиеся биты
При этом хэш вычисляется не напрямую от данных, а с использованием соли. Это добавляет дополнительный уровень защиты: даже если злоумышленник попытается выполнить перебор возможных legacy ID и типов сущностей, он не сможет воспроизвести корректный результат без знания соли. Таким образом, соль не только усложняет обратный анализ UUID, но и снижает риск коллизий при массовой генерации, обеспечивая более надёжную устойчивость всей системы.
Пример кода:
/**
* UUID v8 позволяет создавать собственные алгоритмы генерации,
* сохраняя совместимость со стандартом RFC 9562.
*/
final readonly class UuidFactory
{
private const int FLAG_LEGACY_ID = 1;
private const int FLAG_NEW_ID = 0;
public function createFromLegacyId(EntityType $type, int $legacyId): UuidV8
{
$hash = hash('sha256', $legacyId . $type->value . $this->sharedSecret);
return $this->createUuid(self::FLAG_LEGACY_ID, $legacyId, $type->value, $hash);
}
}
Таким образом, выбор в пользу UUID v8 был продиктован не столько производительностью (здесь v7 объективно быстрее), сколько архитектурными требованиями: миграция legacy данных, совместимость и гибкость.
Второе решение: алгоритм описывающий генерацию UUID v8 в любом сервисе
Чтобы миграция прошла безболезненно, мы разработали собственный алгоритм генерации UUID v8.
Суть — закодировать внутри UUID не только уникальность, но и полезную информацию:
- Флаг Legacy/New
- Позволяет отличить записи, пришедшие из старой базы (int ID), от новых сущностей, которые создаются уже в микросервисах
- Это упростило логику миграции: мы могли обрабатывать старые и новые данные раздельно, без «угадываний»
- Числовой ID
- В UUID закладываются 32 бита под старый int ID
- Благодаря этому мы получили обратное преобразование: из UUID можно достать исходный ID без дополнительных таблиц соответствий
- Тип сущности
- В UUID шифруется тип объекта (например, Staff, Location, Employee)
- Это оказалось удобно для сервисов, где часто нужно быстро понять, к чему относится запись
- Хэш — SHA-256
- Остальные биты UUID занимают данные из хэша
- Он обеспечивает устойчивую уникальность и защищает от коллизий при генерации
Битовая структура (128 бит)
| Flag | Entity ID | Entity Type | Version | Hash | Variant | Hash |
|---|---|---|---|---|---|---|
| 1 | 32 | 15 | 4 | 12 | 2 | 62 |
- Flag (1 бит): 1 = Legacy ID, 0 = новая сущность
- Entity ID (32 бита): Legacy ID или timestamp
- Entity Type (15 бит): до 32 767 типов
- Version (4 бита): 1000 (UUID v8)
- Hash Part1 (12 бит) и Hash Part2 (62 бита): части SHA-256 хэша
- Variant (2 бита): 10 (RFC стандарт)
Типы сущностей
enum EntityType: int
{
case CHAIN = 100;
case LOCATION = 200;
case CLIENT = 402;
case STAFF = 500;
case SERVICE = 600;
// ...
}Обратное декодирование
При работе с новой системой идентификации на базе UUID v8 важно не только уметь генерировать уникальные идентификаторы, но и иметь возможность извлекать из них исходную информацию. Это особенно критично в процессе миграции: миллионы записей из монолита сохраняют свои legacy ID, и нам необходимо быстро и надёжно восстанавливать их при отладке, интеграции со старыми сервисами и анализе логов. Обратное декодирование решает сразу несколько задач: оно позволяет сопоставлять UUID с исходными числовыми идентификаторами без дополнительных таблиц, упрощает трассировку событий в распределённой системе, обеспечивает маршрутизацию данных по типам сущностей и добавляет уровень безопасности за счёт встроенной проверки целостности.
UuidDecoder: извлечение информации
final readonly class UuidDecoder
{
public function decodeFromBinary(string $binaryUuid): LegacyEntityData
{
if (!$this->isLegacyEntity($binaryUuid)) {
throw new UuidNotLegacyException();
}
$fullBitString = $this->mbBytesToBitString($binaryUuid);
$legacyIdBits = mb_substr($fullBitString, 1, 32, 'UTF-8');
$legacyId = (int) bindec($legacyIdBits);
$entityTypeBits = mb_substr($fullBitString, 33, 15, 'UTF-8');
$entityTypeNumber = (int) bindec($entityTypeBits);
return new LegacyEntityData(EntityType::from($entityTypeNumber), $legacyId);
}
}
UUID v8 даёт детерминированные и обратимые идентификаторы: в один UUID можно закодировать флаг legacy/new, 32‑битный legacy ID и тип сущности, а оставшиеся биты заполнить хэшем с солью. Это устраняет необходимость в централизованном маппинге, избавляет от единой точки отказа, делает миграции идемпотентными и упрощает трассировку и маршрутизацию данных в микросервисной среде.
Самый реальный больной пункт — соль. Если она утекла или потерялась, наша проверка хэша теряет смысл, потому что уже выпущенные UUID придётся поддерживать совместимыми, поэтому соль хранится только в Vault.
Второй момент - обратимость: да, удобно вытаскивать legacy ID и тип прямо из UUID, но это делает часть внутренней структуры предсказуемой, так что не стоит туда пихать сверхчувствительные данные — лучше оставить критичные поля в метаданных и полагаться на соль/хэш. И ещё — битовое пространство ограничено: 32 бита под ID и 15 под тип не вечны, если система вырастет, то нужно будет продувать план масштабирование системы генерации UUID.
Бенчмарки и результаты
Производительность генерации
PHP 8.4 + JIT:
- Legacy ID → UUID: ~0.1 ms
- Новый UUID: ~0.15 ms
- Декодирование: ~0.05 ms
Сравнение архитектурных решений
| Подход | Latency | Throughput | Availability | Стоймость поддержки решения |
|---|---|---|---|---|
| CDC Adapter | 12–55 ms | ~1,000 ops/sec | 99.9% | Высокая |
| UUID v7 | 1.78 μs | 561,630 ops/sec | 99.99% | Низкая |
| UUID v8 | 14.37 μs | 69,598 ops/sec | 99.99% | Средняя |
UUID v8 в разы медленнее v7, но на порядки быстрее CDC Adapter и обеспечивает обратную совместимость.
Какие результаты получила наша команда
Мы описали алгоритм генерации UUID v8. На его основе написали библиотеки на требуемых языках программирования и смогли подключать их в тех проектах, где это актуально. Со временем миграции число проектов растет, но не создает никаких трудностей и необходимости индеграции с первоначальным сервисом CDC-адаптером. Таким образом мы сокращаем время разработки и снижаем порог входа разработчикам монолита.
Заключение
UUID v8 даёт практическое решение задачи миграции legacy int ID в микросервисной среде. Решение сочетает детерминированность, обратимость и отказоустойчивость. Внедрение требует внимания к безопасности соли, тестированию и поэтапному планированию миграции. При соблюдении этих условий UUID v8 превращает идентификатор в полезный источник контекста и значительно упрощает сопровождение распределённой системы.