
Рекомендации по быстродействию web-приложений
Если вы стремитесь сделать своё web-приложение более быстрым и не знаете, с чего начать, эта статья именно для вас. Рассмотрим наиболее эффективные техники, которые потребуют изменений только в продуктовом коде приложения.

Введение
Данная статья содержит список рекомендаций к продуктовому коду web-приложений с точки зрения быстродействия и инструкции по их выполнению. Сразу хочется отметить, что в статье вы не обнаружите перечисление микрооптимизаций из-за плохого соотношения "затраченное время - полученная польза" (за крайне редким исключением), приятного прочтения!
Глоссарий
- Модуль - пользовательский интерфейс, реализующий доменную область в продуктовом коде.
- Инициализация - процесс подготовки продуктового модуля к работе, включающий в себя установку начальных значений, минимальную загрузку необходимых данных и настройку компонентов для корректного функционирования и выполнения бизнес-задач клиента.
- Рантайм - процесс использования модуля клиентом, начинающийся после окончания инициализации модуля.
- Статика - файлы, используемые для функционирования приложения (html, js, css, картинки, шрифты и тд).
- Main thread - основной поток планирования и исполнения задач со стороны браузера.
Рекомендации по инициализации web-приложения
Определение минимальной рабочей области
В рамках инициализации модуля нет нужды загрузить и отобразить весь возможный функционала модуля, нам нужно сконцентрироваться на быстрой доставке стабильного и решающего бизнес-задачи клиента интерфейса в рамках текущего ViewPort.
Минимальной рабочей областью модуля является пользовательский интерфейс, который:
- визуально полностью готов к работе в рамках ViewPort - интерфейс не дергается и ведет себя стабильно;
- не блокирует свою функциональность ничем, что может пригодится пользователю "в дальнейшем" (пример - модальные окна);
После определения минимальной рабочей области появится возможность вынести весь функционал, который в неё не входит, либо в фоновую предзагрузку (описано ниже в секции "Предзагрузка"), либо в lazy-loading. Таким образом пользователь получит работающий модуль приложения, время инициализации которого значимо меньше, чем инициализация всего модуля целиком.
Работа с REST API-запросами
Параллелизация
Любые API-запросы, отправляемые модулем приложения на момент инициализации, и которые не зависят от response друг друга, следует запрашиваться параллельно, а не последовательно. Решение об обработке ответов в Promise.all / Promise.allSettled / then решается по требуемой продуктовой логике.
Это достаточно тривиальное правило, но в гонке за доставкой продуктовых фич о нём можно легко забыть
Ранняя отправка
Модулю следует запрашивать необходимые данные для инициализации с API, как можно раньше, в идеале на опережение - часть инициализации минимальной рабочей области модуля ещё не начала происходить, а данные уже есть, либо уже запрошены и ожидают ответа
То есть, если вы уверены, что для завершения инициализации модуля потребуется блок X, которому в свою очередь нужны данные из API-запроса Y - отправьте запрос Y, как можно раньше.
Минимизация получаемого payload
На этапе инициализации модуль должен получать с API минимальный набор данных для отображения рабочей области интерфейса.
Об этом нужно договариваться при проектировании API-контракта с backend-разработчиком, чтобы не загружать излишний объём данных по сети и тем более обрабатывать его под нужды модуля в дальнейшем.
Базовыми решениями в этом подходе может считаться:
- Введение пагинации для API-запросов
- Использование GraphQL / стандарта JSON:API / паттерна BFF
Атомарность
При выборе между 1 большим API-запросом и N малыми предпочтение лучше отдать в пользу N малых, это важно учитывать на моменте проектирования API-контракта с backend-разработчиком.
Критерии "дробления" запросов для каждого приложения уникальны и определяются целевыми показателями быстродействия - кому-то может подойти ответ в 500KB с ожидание response в 1000мс, а кому-то необходим ответ до 10kb с ожиданием response в 100мс.
Базовыми решениями в этом подходе может считаться:
- Не склеивать в одном API-запросе сразу несколько сущностей (коты + собаки). Лучше предоставить для этих сущностей отдельные API-запросы.
- Использование GraphQL / стандарта JSON:API / паттерна BFF
Минимизация больших синхронных вычислительных операций при обработке payload с API
Приложение должно получать с API данные, которые нужно модифицировать, как можно меньше (отсутствие мутации).
Часто данные, получаемые приложением с API, приходится сильно форматировать и "подгонять под frontend". Выражается это различными мапперами, что представляют из себя синхронные математические операции, которые могут создавать большие блокирующие задачи в Main Thread. Базово это решается при проектировании API-контракта.
Однако в случае, если мутации данных на клиенте не избежать и она занимает более 50мс (при CPU тротлинге в 6 раз) - можно вынести эти мутации в WebWorker.
💡Вынесение в WebWorker не является серебряной пулей, т.к. браузеру нужно время на регистрацию воркера и его инициализацию. Если вынесение мутаций в WebWorker оказывает негативное влияние на время инициализации, то необходимо отказаться от его использования в пользу расположения логики мутации в main thread.
Учитываем ограничения HTTP < 2.0
До появления протокола HTTP 2.0 и выше, на стороне клиента мы имели пул из N HTTP-коннектов на каждый API-домен для общения клиент-сервер (у каждого современного движка свои значения, для Chrome это 6). При переполнении количества HTTP-коннектов, API-запросы будут помещаться в очередь и ожидать освобождения одного из коннектов.
Для минимизации эффекта "ожидания потока" на этапе проектирования приложения нужно определиться с приоритетами отправляемых запросов, чтобы модуля на моменте своей инициализации обращался к API только за данными для реализации своей минимальной рабочей области.
Приоритезация запросов реализуется достаточно просто - что JS раньше встречает при выполнении скрипта, то и будет более приоритетным.
Важным считаю отметить тот факт, что данный подход конфликтует с вышеописанным подходом "Атомарность" и в случае отсутствия HTTP >= 2.0 следует деприоритезировать "Атомарность". В идеале иметь две стратегии работы с API: одну для HTTP < 2.0, другую для HTTP >= 2.0.
Проверку на версию HTTP у пользователя можно выполнить c помощью performance.getEntriesByType, данное WebAPI имеет хорошую поддержка браузерами. Пример реализации
function isHttp2Supported() {
if (performance?.getEntriesByType) {
const navigationEntries = performance.getEntriesByType('navigation');
if (navigationEntries.length) {
const {nextHopProtocol} = navigationEntries[0];
return nextHopProtocol === 'h2';
}
}
return false;
}Работа с загружаемой статикой
Сетевой минимализм статики
- Как и с данными, получаемыми по API, приложение должно загружать только ту статику, которая востребована текущей минимальной рабочей областью, остальное должно загружаться через lazy-loading. Если какая-то часть файла нужна на инициализации, а какая-то нет, то:
- В приложении на уровне сборки надо настроить tree-shaking и Code Splitting;
- Можно мануально побить файл на два чанка и загружать их независимо друг от друга, по мере необходимости, если сборщик в вашем приложении с этим не справляется;
- Вся загружаемая статика должна быть минифицирована на уровне сборки приложения для уменьшения передаваемого объёма по сети;
- Статика должна раздаваться с CDN для уменьшения временных затрат при общении клиент - сервер;
- Используйте для изображений формат
webp. Если устройство пользователя не поддерживаетwebp, то можно предоставить fallback изображения в виде любого другого формата.
Важно: изображения при конвертации вwebpмогут увеличиться в размере по отношению к оригиналу, поэтому всегда обращайте внимание на итоговый размер. - Для иконок лучше использовать инструментарий по типу svg-to-ts, вместо подхода со спрайтам (избыточность) и точечной загрузки по сети (плохо масштабируется для HTTP < 2.0). Этот подход и минимизирует сетевой трафик и не загружает избыточные данные;
- Настройте сборку приложения и его релиз таким образом, чтобы минимизировать инвалидацию кеша статики у пользователей;
Пример: В приложении из 15 модулей планируется релиз с изменением только в модуле X. При сборке приложения хэши должны поменяться только у тех чанков, которые относится к модулю X, остальная статика должна остаться в неизменном виде.
Учитываем ограничения HTTP < 2.0
Само ограничение схоже с ограничением для API, однако количество HTTP-коннектов для загрузки статики больше (для Chrome 20 на каждый домен). Модерировать и приоритезировать каждый файл статики в приложении является крайне трудозатратным занятием и лучше всего придерживаться двух правил:
- Соблюдать принцип "Сетевого минимализма";
- Настроить сборку приложения с учетом баланса "размер чанка - количество чанков".
Если загружаем 1 чанк на 1 MB - плохо, так как браузер будет долго его обрабатывать (описано в следующей секции), если загружаем 100 чанков по 10kb - плохо, так как будем упираться в ограничения HTTP < 2.0.
Можно держать за ориентир trashhold по суммарному количеству js + css чанков для каждого из модулей в пределах 150;
Работы с исполнением кода
Минимализм исполнения js-кода в main thread
Объём js-кода, загружаемого по сети != объёму его выполнения. Выполнение js-кода порождает в main thread самые большие и долгие задачи (вплоть до 2+ секунд) - script evaluate. Для избавления от избыточности выполняемого кода нужно:
- Использовать профилирование и разбирать каждый случай такой задачи в отдельности
💡Универсального рецепта здесь нет, однако избыточность выполнения обычно сигнализирует о том, что одна и более рекомендаций, приведенных в этой статье, не выполняются.
- Если выполняемая логика не содержит непосредственную работу с DOM, то можно:
- Переместить в WebWorker, однако надо держать в голове ограничения данного подхода, описанные выше;
- Разбить одну большую задачу на более мелкие посредством одного из подходов:
- requestIdleCallback - если одну из частей задачи можно выполнить в моменты простоя браузера, то есть с низким приоритетом;
- queueMicrotask - если одну из частей задачи можно отложить, но хочется сразу запланировать её выполнение в текущем стеке вызовов;
- Вынести на backend;
- Если выполняемая логика содержит работу с DOM, то зачастую это единовременный рендер больших объёмов повторяющихся данных (например, таблицы / списки) и следует идти по следующему алгоритму:
- Убедитесь, что вы следуете подходу "Сетевого минимализма" для рендера;
- Убедитесь, что вы используете подход "Виртуализация" (описан ниже в секции "Рантайм");
- Обсудите с дизайнером возможные пути по сокращению количества элементов для рендера:
- Увеличить размер повторяющихся элементов (дополнить контентом, увеличить отступы и тд);
- Уменьшить контейнер в котором происходит рендер повторяющихся элементов;
- Сделать рендер элементов двухэтапным: сначала превью (не скелетон), затем полное отображение. При этом полное отображение можно рассмотреть в контексте мануального управления - пользователь кликнул / навёлся на элемент и получил полную информацию;
- Если код реализует абсолютно независимый функционал от остального интерфейса (например, чат-бот), то можно рассмотреть вариант помещения этого кода в iframe. С использованием iframe часто браузер будет открывать для него новый поток исполнения помимо main thread и итоговая инициализация модуля может сильно уменьшиться;
Предотвращение паразитных style recalculation / layout / reflow
В процессе инициализации модуля браузер производит много планового рендера, однако неаккуратная реализация кода может повлечь за собой большое количество излишних перерисовок и пересчета стилей, которые в зависимости от размера DOM могут достигать 500мс и более. Их можно обнаружить с использованием профилирования. Для устранения излишних задач по рендеру необходимо:
- Избегать использования js-операций, которые обращаются напрямую к элементам DOM (даже для чтения). Список опасных операций. Если для реализации продуктовой логики необходимо использовать одну из операций в списке, то нужно предусмотреть кеширование (описано далее в статье) результата выполнения данной операции, чтобы обращаться к нему, а не производить операцию повторно;
- Избегать изменения геометрических размеров элементов средствами
cssпосле их монтирования; - Быть осторожнее с использованием will-change и прибегать к нему только в случаях, когда другого пути нет. Массовое использование
will-changeможет привести к увеличению размеров потребляемой приложением памяти и её утечкам; - Использовать
position: absolute/position: sticky/position: fixedдля кейсов, когда нужно отрисовать нагруженный элемент и он не влияет на позиционирование других элементов;
Рекомендации по рантайму web-приложений
Предотвращение утечек памяти
В рамках жизненного цикла модуля создаётся достаточно большое лексическое окружение, которое при размонтировании само по себе не очищается и будет оказывать влияние на последующий рантайм приложения в контексте потребляемой памяти. Браузер помогает нам в очистке лексического окружения благодаря механизму garbage collection, однако для его корректной работы со стороны кода модуля следует помочь ему в этом:
- При размонтировании модуля / части модуля производить отписку от событий, на которые были подписаны мануально через
addEventListener; - Если используется
setTimeout/setInterval, то очищать их черезclearTimeout/clearInterval, в случаях, если их логика больше не нужна или происходит размонтирование модуля / части модуля; - Очищать излишние данные во внешних хранилищах (
IndexedDB,LocalStorageи тд), если они больше не потребуется в реализации продуктовых сценариев; - Производить полное размонтирование DOM-нод вместо их кеширования (например, скрытие через
display: none), если пользователь скорее всего больше не будет с ними взаимодействовать, либо это взаимодействие крайне редкое. Универсального рецепта для определения "крайне редко" нет, это достаточно субъективное восприятие, которые нужно обсуждать в команде при разработке продуктовой фичи; - Не прибегать к неявной мутации сущностей. Если для реализации продуктовой логики необходимо производить неявные мутации данных с сохранением локальной копии - при размонтировании обязательно производить очистку локальной копии через явное присваивание к
null;
Пример: Модуль X создает локальную копию объекта Y и кладёт её в Z, при изменении Z происходит мутация Y т.к. они связаны по ссылке. При размонтировании модуля X нужно приравнять Z кnull, чтобы garbage collector мог удалить неиспользуемые ссылки.
Предотвращение реагирования на спам DOM-событий
Некоторые DOM-события могут происходить очень часто (resize, scroll, input, keydown, click и т.д.) и если приложение производит нагруженную обработку этих событий, то MainThread приложения может сильно забиться, что приведёт к зависанию пользовательского интерфейса. Следует реагировать на такие частотные события дискретно:
- debounce - если из повторяющихся событий интересует самое последнее. Пример - обработка ввода текста в поле поиска;
- throttling - если требуется ограничить частотность обработки. Пример - нажатие на кнопку;
Lazy-loading
Виртуализация
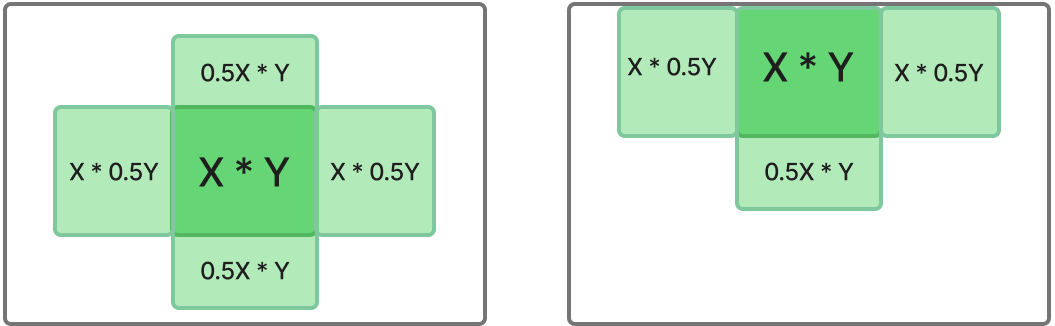
При рендеринге повторяющихся элементов (например, списки) использовать virtual-scroll, либо же кастомные реализации через IntersectionObserver, главная цель - рендерить и держать в DOM-дереве минимальное количество повторяющихся элементов. При этом если не производить "опережающий рендер", то приложение начнёт терять UX, так как интерфейс станет дёрганным. Можно следовать следующей схеме по количеству элементов в контейнере:
Формула расчета
$ElementsCount = 2 * (X * 0.5Y) + X * Y + 2 * (0.5X * Y), где
* ElementsCount - количество элементов, которые должны быть отрисованы в контейнере
* X - количество элементов, помещающиеся во ViewPort контейнера по вертикали
* Y - количество элементов, помещающиеся во ViewPort контейнера по горизонталиСхематично это должно выглядеть таким образом:

Главное правило - область контейнера с отрисованными элементами следует за ViewPort контейнера
Фасадирование
Если какая-то часть модуля не видна пользователю на инициализации модуля (например, модальные окна), то следует загружать статику для таких частей и инициализировать её через подход on-demand lazy-loading, т.е. при её действительной необходимости. В чистом виде on-demand lazy-loading не является user-friendly решением, т.к. при совершении тригерного действия загрузки пользователь просто сидит и ждёт. Именно поэтому лучше использовать подход "Фасадирование" - предоставление на моменте инициализации модуля легковесной обертки, для lazy-loading'а определенной части модуля. Эта обертка должна:
- Содержать логику по загрузке требуемой статики и её инициализацию при определённом тригерном событии (например, нажатие на кнопку, которая должна открыть модальное окно);
- Иметь минимальный ui, зачастую просто скелетоны + корневой контейнер, для идентификации загрузки;
- Быть легковесной - до 10kb;
- ScriptEvaluate при инициализации не должен превышать 50мс при замедлении CPU в 6 раз;
- Предзагружать необходимые API-данные для части модуля, которую она загружает и инициализирует (подход описан ниже в секции "Предзагрузка");
Кеширование
Синхронные вычисления
Если произведено какое-то вычисление (математическое, связанное с DOM), которое можно переиспользовать в дальнейшем для избегания повторного выполнения вычисления - нужно закешировать этот результат и использовать при повторном обращении. Кеш вычисления может лежать в достаточно обширном количестве мест и его итоговое расположение зависит от продуктовых потребностей, приведу самое популярное:
- Локальный кеш в рамках кода модуля - любые данные, которые могут переиспользоваться только в рамках модуля и его текущего жизненного цикла;
- LocalStorage - примитивные легковесные данные (суммарно до 5МБ), которые нужны не только в рамках текущей сессии, но и последующих;
- SessionStorage - примитивные легковесные данные (суммарно до 5МБ), которые нужны только в рамках текущей сессии;
- IndexedDB - средне-крупные данные любого типа, которые могут потребоваться в том числе при повторной инициализации приложения;
Особенности работы с локальным кешом
При использовании локального кеша (например, object / weakMap и т.д.) следует:
- Контролировать его размер - не превышать 200kb, это можно проверять на вкладке Memory в DevTools;
- Иметь стратегию инвалидации, если кеш неактуален - чистить;
- При превышении допустимого размера и появлении новых значений удалять самые неактуальные значения исходя из стратегии инвалидации ;
Отрисовка
Если отрисован нагруженный блок (затрачиваемое время занимает более 100мс при тротлинге CPU в 6 раз) и его необходимо убрать из ViewPort пользователя, но через какое-то время показать заново, то следует:
- Не вырывать блок из DOM, а повесить на него
display: noneлюбым удобным способом в рамках приложения; - Определить время, через которое блок точно должен быть уничтожен для минимизации влияния на размер DOM. Базово таким временем ожидания можно считать 5 минут с момента последнего скрытия блока. Если по истечении выбранного времени пользователь заново не увидел блок - можно удалять из DOM;
Keep-alive
Keep-alive это хороший подход для минимизации расходов на инициализацию модулей / частей модуля, однако слишком большие объёмы могут негативно сказаться на потребляемую приложением память. Следует соблюдать размер кеша в keep-alive до 50% суммарных размеров статики его родительского модуля.
Регулировать размер кеша в keep-alive можно мануально в коде, либо с предоставляемым фреймворками инструментарием (например, динамическое значение exclude / использование опции max cached instances для Vue).
Пример: Модуль X, с суммарным весом в 100kb, имеет часть Y, которая использует keep-alive. Значит размер кеша в Y должен быть меньше 50kb.
Работа с API-запросами
Работа с API в рантайме включает в себя все направления деятельности по работе с API на инициализации, описанными ранее в статье, но и имеет свои специфичные механики.
Предзагрузка
При реализации продуктовой логики стоит держать в голове путь, который проходит пользователь по интерфейсу для решения своих задач и исходя из этого пути производить предзагрузку тех данных из API, которые скорее всего ему потребуется. Предзагрузка данных из API должна:
- Следовать рекомендациями по работе с API из данной статьи;
- Являться фоновым процессом и не приводить к замедлению текущего интерфейса;
- Начинаться строго после окончания инициализации модуля;
- Опираться на аналитические данные, а не субъективные ощущения. Мы не сможем "угадать" данные для 100% пользователей, но нужно к этому стремиться;
Отсутствие спама
Если в продуктовой логике может происходить спам к одному и тому же API-запросу (реагирование на частые события клика / нажатия клавиш, обработка поиска и тд) при получения response от которого приложение производит нагруженные синхронные операции, то для обработки таких кейсов рекомендуется использование:
- debounce - если нужно отправлять в API самый актуальный payload при повторяющихся событиях. Хорошо подходит для сценария "поиск";
- throttling - если нужно отправлять в API любой payload с равными интервалами времени. Хорошо подходит для частых расчетов;
Работы с исполнением кода
Подходы в рантайме полностью повторяют подходы для инициализации, описанные в секции "Инициализация".