
Как не упасть вместе с сервером: строим офлайн-режим на Service Worker и IndexedDB
Для кого: фронтенд-разработчики, которые слышали про Service Worker, но никогда не работали с ним на практике. Никакого предыдущего опыта не требуется — только базовый JavaScript и понимание того, как браузер делает HTTP-запросы.
🔥 Пролог
Представим: 9 утра, пик записей. Мастер открывает расписание — белый экран. Через минуту в поддержку летят первые тикеты, через тридцать — сотни. Администраторы не видят записи, мастера не знают расписание, клиенты не могут записаться.
А нам и представлять не нужно — мы через это прошли.
После первого такого инцидента мы поставили себе цель: следующий раз пользователи не должны заметить, что сервер упал. Никаких белых экранов, никаких потерянных расписаний — приложение продолжает показывать данные, пока мы разбираемся с проблемой. Вот что мы для этого построили.
Кратко о чём статья:
- Service Worker перехватывает запросы — используем как прокси при инцидентах
- Incident Manager в двух экземплярах: в main-thread и прямо внутри SW
- Cache Storage для HTML, IndexedDB для данных
- Thundering herd при выходе из офлайна — решаем через стратегии с сервера
- Деплой SW — отдельная дисциплина с двухфазным релизом
⚙️ Часть 1. Прокси прямо в браузере
Что такое Service Worker
Service Worker — это скрипт, который браузер запускает в фоне, отдельно от вашей вкладки. Живёт по своим правилам: нет доступа к DOM, не может напрямую менять страницу, зато умеет кое-что важное — перехватывать все сетевые запросы.
Каждый раз, когда страница делает fetch — запрос к API, загрузка картинки, получение HTML — этот запрос проходит через Service Worker. Воркер сам решает, что с ним делать: пропустить к серверу, вернуть из кеша или вообще сформировать ответ самостоятельно.
┌──▶ Сервер
Браузер ──▶ SW ─┼──▶ Кеш
└──▶ Свой ответ
Регистрация: постоянная. Процесс: нет
// В обычном JS вашей страницы
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/service_worker.js')
}
Здесь важно понять одну вещь, которая поначалу сбивает с толку. У Service Worker есть два разных понятия:
Регистрация — это запись в браузерной базе данных: «для этого сайта есть воркер вот с таким скриптом». Она живёт постоянно — переживает закрытие вкладок, закрытие браузера, перезагрузку компьютера. Удаляется только при явном unregister() или очистке данных сайта.
Процесс воркера — это уже выполняющийся код. И вот он эфемерен: браузер убивает его, когда воркер простаивает (конкретный таймаут у каждого браузера свой, стандарта нет). Закрыли все вкладки — через какое-то время процесс умрёт.
Но как только приходит новый fetch-запрос или postMessage — браузер поднимает процесс заново. И вот тут важный момент: при каждом перезапуске скрипт выполняется с нуля, все глобальные переменные сбрасываются. Хранить долгоживущее состояние в памяти воркера нельзя — оно не переживёт следующую «спячку».
Жизненный цикл: установка, ожидание, активация
Когда браузер обнаруживает изменённый файл воркера, он не заменяет старый немедленно — проходит три стадии:
installing → waiting → active
Installing — браузер скачивает новый скрипт и запускает событие install. Хорошее место, чтобы положить ресурсы в кеш.
Waiting — новый воркер установлен, но не активирован. Браузер ждёт, пока все вкладки под старым воркером будут закрыты. Логика: нельзя менять воркер у вкладки прямо посреди её работы.
Active — старые вкладки закрыты, новый воркер занял место и начинает перехватывать запросы.
Это значит: задеплоили новую версию воркера — пользователи, у которых открыта вкладка, будут работать на старом ещё долго. Иногда — до следующего дня.
Хм, а что если нам нужно обновить воркер срочно? Ждать, пока пользователь сам закроет вкладку?
Именно для этого существует skipWaiting() — команда, которая говорит воркеру «не жди, активируйся прямо сейчас». Как именно мы это используем — разберём в части про деплой. Сначала — нужно понять, что сервер вообще упал. И это уже нетривиально.
🚨 Часть 2. Кто первым узнает, что всё сломалось
Проблема: Service Worker не знает про инциденты
SW перехватывает запросы. Отлично. Но сам по себе он не знает, почему сервер не отвечает: временный таймаут, плановое обслуживание или инцидент на три часа?
Это критично, потому что поведение должно отличаться:
- Сервер лагнул на секунду → повторяем запрос
- Идёт инцидент → переключаемся в офлайн-режим, показываем данные из кеша
Нужен внешний источник правды о состоянии системы.
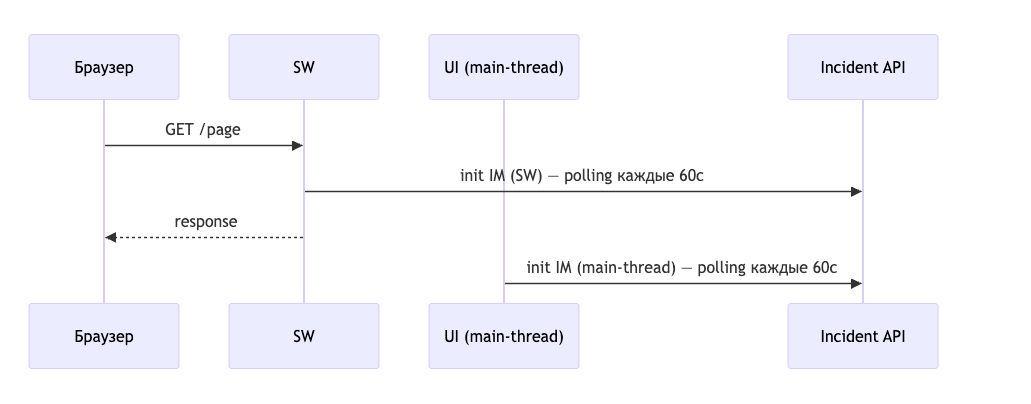
Incident Manager и polling
Мы сделали отдельный Incident API — лёгкий endpoint с доступностью на уровне CDN, независимый от основного бэкенда. Отвечает на один вопрос: система сейчас доступна или нет?
GET /incident/status → { "available": true/false, "strategy": {...} }
Incident Manager — модуль, который каждые 60 секунд спрашивает этот API и рассылает события:
enhanced-mode-activated → всё, переходим в офлайн
enhanced-mode-deactivating → сервер восстанавливается, ждём...
enhanced-mode-deactivated → можно работать в обычном режиме
А что если вкладки нет вообще?
Вот где нас первый раз поймал SW. Регистрация воркера живёт независимо от вкладки — пользователь закрыл журнал записи, но регистрация осталась. Когда он откроет /signin, воркер поднимется снова и перехватит запрос.
Инцидент начался именно в этот момент — кто про него знает, если main-thread не поднялся?
Ответ: SW должен знать про инцидент сам, без помощи вкладки.
Поэтому Incident Manager существует в двух экземплярах:
- В main-thread (обычный JS во вкладке) — управляет UI, показывает баннеры
- Прямо внутри Service Worker — работает автономно, влияет на логику перехвата запросов
Оба запускают свой цикл polling. Это не дублирование — это гарантия: даже если main-thread не запустился, SW всё равно знает про инцидент и правильно обработает следующий fetch.
Общаются они через postMessage:
// Main-thread → SW: сообщаем про состояние сети
navigator.serviceWorker.controller.postMessage({
type: 'network-status-changed',
payload: { isOnline: navigator.onLine }
})
// SW → все вкладки: рассылаем событие инцидента
clients.matchAll().then(clients => {
clients.forEach(client => client.postMessage({ type: 'enhanced-mode-activated' }))
})
📦 Часть 3. Cache-first: отдавай из кармана
Стратегия перехвата запросов
SW знает, что идёт инцидент. Что делать с входящими запросами?
Основная стратегия для HTML-страниц — Cache First:
- Пришёл запрос? Сначала смотрим в кеш
- Нашли — отдаём из кеша, не идём в сеть вообще
- Не нашли — идём в сеть, и если успешно — кладём в кеш на будущее
self.addEventListener('fetch', event => {
if (isHtmlRequest(event.request)) {
event.respondWith(handleHtml(event))
}
})
async function handleHtml(event) {
const cached = await caches.match(event.request)
if (cached) return cached
const response = await fetch(event.request)
cache.put(event.request, response.clone()) // (1)
return response
}
(1) Почему
clone()? ОбъектResponse— это поток (stream). Прочитать его можно только один раз: либо вы отдаёте его браузеру, либо кладёте в кеш.clone()создаёт копию потока — один экземпляр уходит в кеш, второй возвращается как ответ на запрос.
Страница расписания: чуть сложнее
Страница расписания — /timetable/:salonId — собирается из двух частей:
- HTML-шаблон — структура страницы
- Переводы i18n — тексты на нужном языке
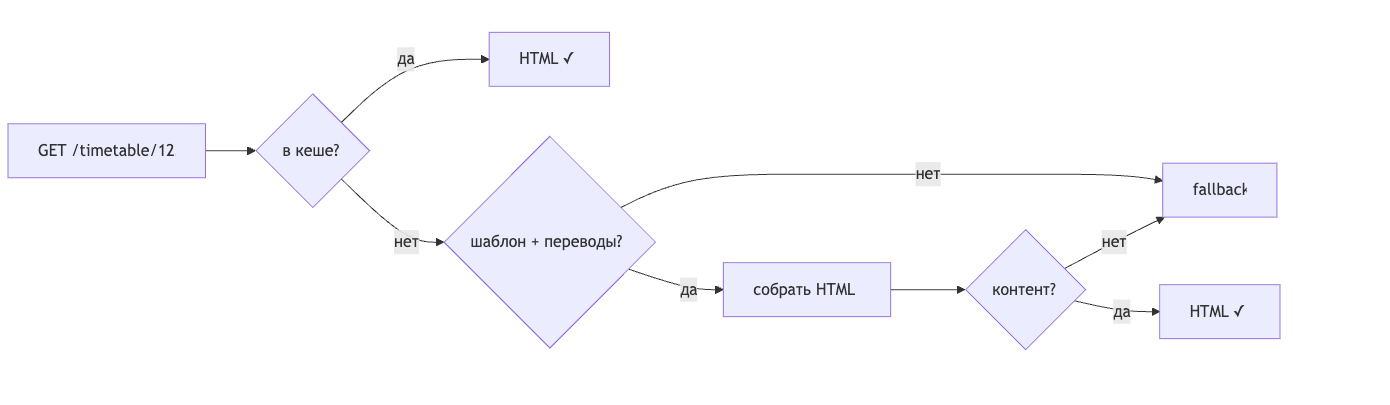
В кеше они хранятся отдельно. Когда приходит запрос на /timetable/123, SW собирает ответ на лету:
Есть готовый кешированный HTML? → отдать сразу
Нет:
1. Достать HTML-шаблон из кеша
2. Достать переводы из кеша
3. Встроить переводы в шаблон
4. Вернуть собранный HTML
Что-то не нашлось → fallback (офлайн-заглушка)
На каждом шаге — fallback. Не удалось собрать ответ? Не 500-я ошибка, а специальная офлайн-страница с понятным сообщением.
Куда кладём кеш
SW использует Cache Storage — браузерное хранилище специально для HTTP-ответов. Не localStorage, не sessionStorage — именно Cache Storage, который умеет хранить полноценные Response объекты.
const cache = await caches.open('my-app-v2.0.0')
await cache.put(request, response)
Версия в названии — не случайность. При обновлении воркера старый кеш удаляем, создаём новый. Подробнее — в части про деплой.
HTML отдаём. Но страница расписания без данных о мастерах и записях — красивая пустышка.
🗄️ Часть 4. Данные тоже хотят жить
HTML есть. Данных нет
Закешировали HTML-страницу расписания. Отлично, пользователь увидит структуру.
Но расписание — это не просто HTML-скелет. Это данные: мастера, услуги, записи клиентов. Они приходят через API и живут в памяти приложения.
Как сохранить их так, чтобы они пережили перезагрузку страницы и были доступны в офлайне?
Cache Storage здесь не поможет — он хранит HTTP-ответы, а не структурированные данные, с которыми удобно работать в JS. Нужна IndexedDB.
IndexedDB: локальная база прямо в браузере
IndexedDB — полноценная NoSQL база данных в браузере. Хранит данные постоянно, поддерживает транзакции, работает асинхронно, доступна и из main-thread, и из Service Worker.
У нас две базы:
salon-database — данные конкретного салона:
companies— информация о компанииresource_instances— мастера и оборудованиеtimetable_*— данные расписания
Структура хранения следующая: в каждом store лежит одна запись на салон — ключ salonId, значение — массив объектов. Проще, чем хранить каждый объект отдельно, и хорошо работает для сценария «загрузить всё сразу для одного салона».
dictionary-database — глобальные справочники:
countries— список странpreloaded_salons— маркер того, что данные по салону успешно предзагружены
Preload: готовимся заранее, пока всё хорошо
Офлайн-данные нельзя достать из воздуха в момент падения сервера. Их нужно предзагрузить заранее.
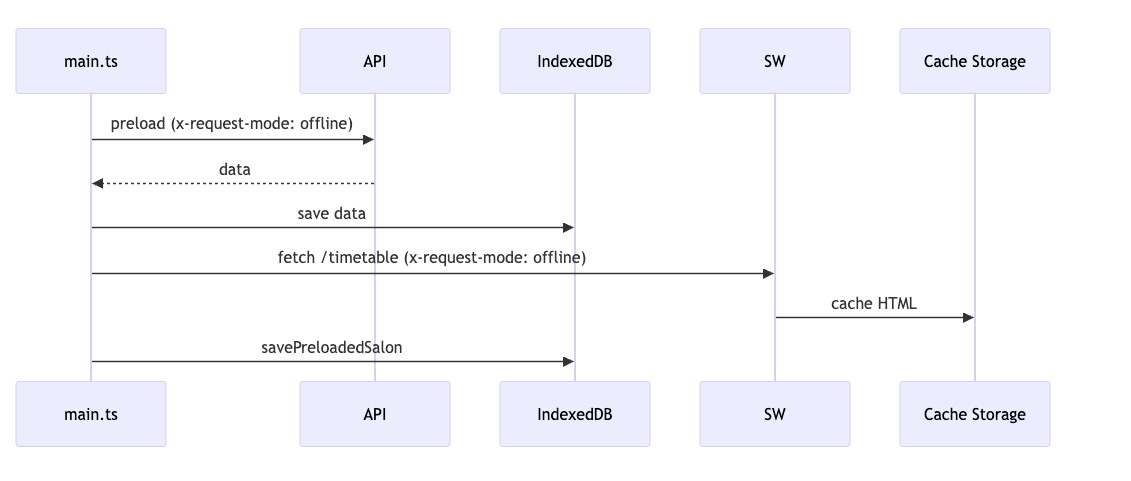
При запуске приложения (в online-режиме):
Для каждой нужной сущности:
→ Запрашиваем API с заголовком x-request-mode: offline
→ Сохраняем в IndexedDB
Для нужных HTML-страниц:
→ Делаем fetch с x-request-mode: offline
→ SW перехватывает и кладёт в Cache Storage
Помечаем салон как «предзагруженный»
Когда приложение переходит в офлайн, логика получения данных переключает источник:
const getResourceInstances = async (salonId) => {
if (OfflineModeService.isOfflineMode) {
return await getResourceInstanceService().getAll(salonId) // IndexedDB
}
return await resourceInstancesApi.getResourceInstances() // API
}
А что если все клиенты стартанут preload одновременно?
Хороший вопрос, и мы о нём тоже подумали. Сервер восстановился после инцидента. Все вкладки одновременно получают сигнал «можно!» — и все 10 000 из них идут обновлять данные через API. Сервер только поднялся, но, видимо, не надолго.
Это называется thundering herd — «стадо громкого топота».
Решение — jitter-ожидание перед стартом preload:
MIN_WAITING_TIME = 30 секунд (раньше не стартуем)
MAX_WAITING_TIME = 5 минут (к этому моменту стартуем гарантированно)
Каждые 2 секунды:
если прошло < MIN → ждём
если прошло >= MAX → стартуем
иначе:
вероятность старта = прошло / MAX (растёт с 0 до 1)
бросаем монетку с этой вероятностью
Чем дольше ждёт клиент — тем выше вероятность старта. Нагрузка «размазывается» во времени вместо единого пика.
Текущее время ожидания сохраняется в
localStorage. Пользователь перезагрузил страницу посреди ожидания — счётчик не обнуляется, продолжает с того места.
Важный момент: офлайн-режим у нас readonly
Всё, что мы описали — это про чтение данных: расписание, мастера, записи. В офлайн-режиме пользователи видят актуальные (на момент preload) данные, но не могут создавать новые записи или вносить изменения — запросы на запись блокируются и пользователь видит понятное объяснение.
Это осознанное решение. Потому что стоит разрешить запись — сразу возникают вопросы: а что если кто-то уже записал клиента в то же время из другого браузера? Как разрешать конфликты? Нужен ли optimistic UI? Это отдельная и очень нетривиальная тема — возможно, разберём в следующей статье.
Вход в офлайн отработал. Теперь — выход. И вот тут мы положили сервер второй раз.
🔄 Часть 5. Сервер ожил — не торопись
Thundering herd, второй раз
Мы научились входить в офлайн-режим. Теперь — выход.
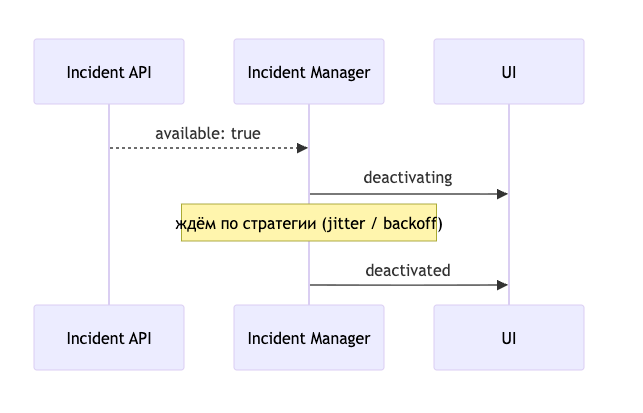
Incident Manager получает от Incident API: available: true. Восстановились!
Казалось бы, переключаем флаг и работаем как раньше. Но тут та же проблема что с preload: если все клиенты одновременно пойдут к только что ожившему серверу — мы сами его положим обратно. Один раз мы уже так делали.
Поэтому Incident API вместе со статусом available присылает стратегию выхода:
Две стратегии
Randomized Jitter — каждый клиент получает случайную задержку от 0 до N секунд. Все равны: нет никаких приоритетов, просто равномерное размазывание нагрузки во времени.
Capped Exponential Backoff — задержка растёт экспоненциально в зависимости от того, сколько клиент уже провёл в офлайне: чем дольше ждал — тем дольше ещё подождёт перед выходом. Те, кто только что открыл браузер, выйдут первыми. Те, кто провёл в офлайне несколько часов, получат бо́льшую задержку. Сверху она ограничена — никто не ждёт вечно.
Ключевая деталь: параметры стратегии хранятся в IndexedDB. Пользователь перезагрузил страницу посреди ожидания — он продолжит ждать столько, сколько нужно, а не начнёт заново.
Система работает. Но есть ещё одна проблема, о которой мы узнали на проде — и которую вы скорее всего не найдёте в документации.
🚀 Часть 6. Как задеплоить и не сломать мир
Service Worker — это не обычный JS-бандл
Привычная схема: задеплоил → пользователи получили новый код. С Service Worker так не работает, и мы это узнали на проде.
Проблема первая: агрессивное кеширование
Браузер кеширует service_worker.js очень агрессивно. Единственный способ заставить его обновить воркер — изменить содержимое файла. Поэтому URL должен оставаться стабильным — в отличие от обычного JS (app.a3f5c.js), где хеш меняется при каждом деплое.
Браузер периодически перечитывает файл по зарегистрированному URL и сравнивает байты. Изменились — запускает стандартный цикл installing → waiting → active. Если бы URL менялся при каждом деплое, браузер воспринимал бы это как новую регистрацию для того же scope — полный цикл переустановки без нужды.
Проблема вторая: воркер грузит дополнительные файлы
У нас логика разбита по файлам, и воркер загружает их через importScripts:
// service_worker.js
var SW_VERSION = "2.0.0"
importScripts(`./sw-static/version-${SW_VERSION}/router.js`)
importScripts(`./sw-static/version-${SW_VERSION}/loaders/incident_manager_loader.js`)
Проблема третья: поэтапная раскатка по серверам
У нас не один сервер — их много, балансировщик распределяет запросы между ними. Деплоим мы поэтапно.
Вот реальный сценарий, который нас поймал: обновили service_worker.js с SW_VERSION = "2.1.0" на половину серверов. Браузер скачал новый воркер с сервера A. Воркер пытается загрузить sw-static/version-2.1.0/router.js. Страница обновилась — пользователь попал на сервер B, где этой папки ещё нет.
importScripts падает с 404. Воркер сломан у части пользователей.
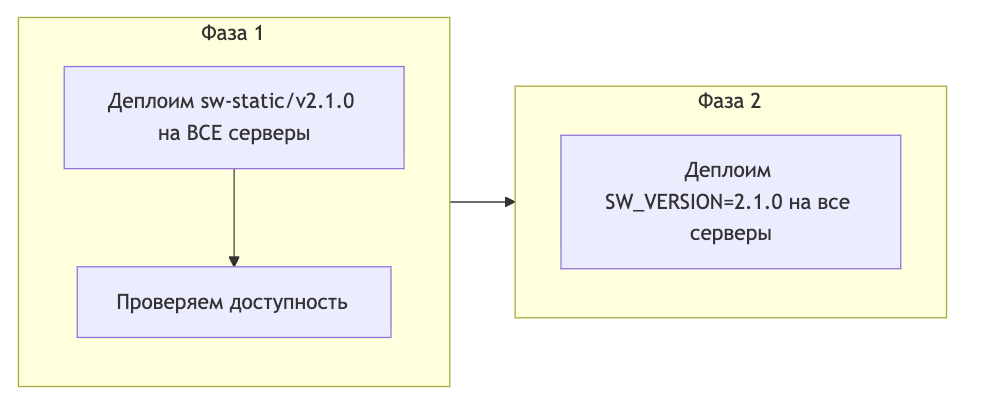
Двухфазный релиз
Решение простое, когда понимаешь причину:
Фаза 1 — сначала раскладываем новую статику:
Создаём: sw-static/version-2.1.0/ со всеми файлами
Деплоим на ВСЕ серверы
Проверяем: curl /sw-static/version-2.1.0/router.js → 200 OK
Фаза 2 — только после этого меняем версию воркера:
Обновляем SW_VERSION = "2.1.0" в service_worker.js
Деплоим на все серверы
К моменту, когда браузеры начнут скачивать новый воркер, все нужные файлы уже есть на каждом сервере.
«Шторм перезагрузок»
Двухфазный релиз решает проблему с 404, но во время Фазы 2 есть другой эффект. Пока раскатка service_worker.js не завершена, разные вкладки могут попасть на разные серверы и скачать разные версии воркера.
Браузер держит только одну активную версию SW для домена. Когда вкладка скачала новый воркер — он пытается вытеснить старый. Срабатывает механизм sw-global-reload, остальные вкладки перезагружаются. Но при перезагрузке они снова могут попасть на другой сервер — скачать другую версию — снова перезагрузить соседние вкладки.
Пока все серверы не выкатят одинаковую версию — вкладки будут периодически перезагружаться.
Это ожидаемое поведение во время раскатки. Именно поэтому важно не затягивать Фазу 2 и доводить деплой до конца, а не оставлять «полкластера на старом, полкластера на новом». И лучше делать это в малонагруженное время.
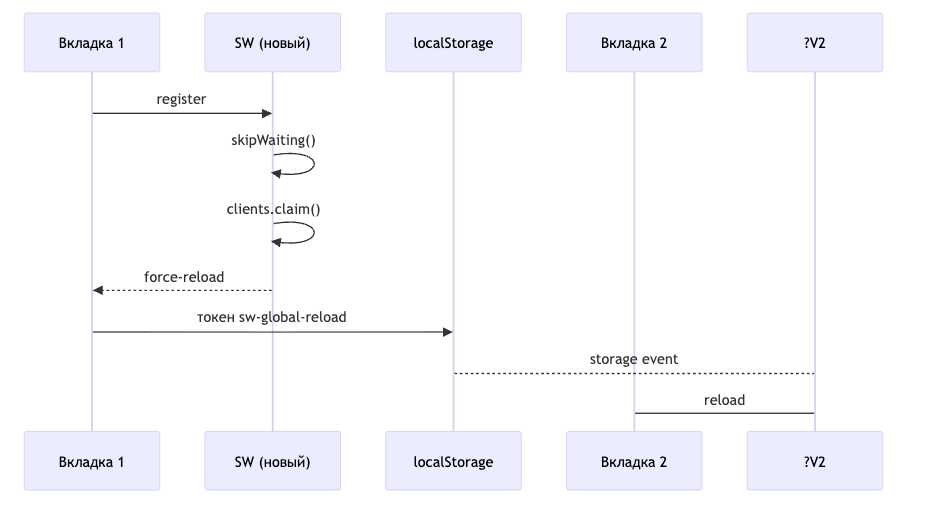
Как новый воркер обновляет все вкладки
Установили новый воркер — нужно, чтобы все открытые вкладки перезагрузились и начали работать под ним. Без этого получаются «зомби-вкладки» на старой логике.
Механизм:
ServiceWorkerManagerотправляет в новый воркер{ type: "app-version" }- Воркер вызывает
skipWaiting()— ускоряет активацию, не ждёт закрытия старых вкладок - При активации делает
clients.claim()и рассылает всем вкладкамforce-reload - Параллельно
ServiceWorkerManagerпишет токен вlocalStorage['sw-global-reload'] - Другие вкладки ловят
storageсобытие и перезагружаются один раз на токен
Итог: все вкладки приходят к одной версии воркера автоматически.
🔴 Часть 7. Аварийный рубильник
Всё это хорошо работает в штатном режиме. Но что если мы сами задеплоили баг в воркер?
Важно понять: воркер закеширован в браузере. Даже если вы уже задеплоили исправление на сервер, старый сломанный воркер продолжает жить у пользователей. Он перехватывает запросы и ломает работу — а пользователь ничего не может сделать, просто обновляя страницу.
Если нужно убить воркер вручную (например, вы разработчик и хотите почиститься):
- DevTools → Application → Service Workers → Unregister
- Или: DevTools → Application → Storage → Clear site data (удалит воркер + весь кеш)
- Или консоль:
navigator.serviceWorker.getRegistrations().then(rs => rs.forEach(r => r.unregister()))
Но это работает только для вас. Чтобы убить воркер у всех пользователей, нужен системный механизм.
На такой случай есть feature flags:
offline_mode_global— глобальный рубильникoffline_mode— для конкретного филиала
Если флаги выключены, приложение отправляет в SW команду на самоуничтожение:
// main.ts — если флаг выключен
swManager.postMessage({ type: 'destroy-service-worker' })
// service_worker.js — получает команду и удаляет себя
self.addEventListener('message', event => {
if (event.data.type === 'destroy-service-worker') {
self.registration.unregister()
clients.matchAll().then(clients =>
clients.forEach(c => c.navigate(c.url))
)
}
})
Выключили флаг в панели администратора → при следующей загрузке страницы воркер получит команду и удалит себя. Никаких ручных действий со стороны пользователей.
✅ Итого
Что мы построили:
| Слой | Что делает |
|---|---|
| 🔍 Мониторинг | Incident Manager в main-thread и SW опрашивает Incident API каждые 60 секунд. Знает про инциденты раньше, чем пользователь увидит ошибку. |
| 📄 Кеширование | SW перехватывает запросы и отдаёт HTML из Cache Storage, пока сервер недоступен. Пользователь видит заглушку, а не белый экран. |
| 🗄️ Данные | Preload заранее скачивает нужные сущности в IndexedDB. В офлайне приложение читает из локальной базы вместо API. |
| 🐢 Плавный выход | Jitter размазывает нагрузку равномерно, exponential backoff даёт приоритет тем, кто открыл браузер позже. Сервер не получает навал сразу после восстановления. |
| 🛡️ Безопасный деплой | Двухфазный релиз и feature flags дают контроль без риска сломать пользователей. |
Что оказалось неочевидным
Когда начинали, казалось: «Service Worker — это просто кеш-прокси, делов-то». На практике:
🧩 Регистрация SW переживает вкладку, процесс — нет. Браузер убивает процесс воркера при простое и поднимает заново на каждый fetch. Глобальные переменные сбрасываются. Если нужно что-то сохранить между «спячками» — только IndexedDB или Cache Storage, не память.
🧩 Два инстанса одного модуля — Incident Manager в main-thread и в SW — это два разных окружения с разными транспортами для событий. Нужно проектировать модуль так, чтобы он адаптировался к обоим.
🧩 Деплой SW — отдельная дисциплина — двухфазный релиз, шторм перезагрузок, агрессивное кеширование. Привычный подход «задеплоили и забыли» тут не работает.